Clear Street is a fintech building modern infrastructure for capital markets and reimagining the legacy workflows and silos that are essential to increasing access in the financial markets, all while transparently decreasing risks and costs.
Our platform is built on a modern foundation designed around Kafka and tightly integrated into the AWS cloud, giving us horizontal and vertical scalability. Our architecture lets us easily decompose complex finance business logic into manageable chunks, or microservices, and Kafka’s democratization of data access and data flows make it easy for us to create an event-sourced architecture.
However, we’ve learned along the way that even modern technology, like Kafka, sometimes needs a new approach and that the most common approaches aren’t always the most effective. This is why we decided to move from Avro to Protobuf on Kafka.
Back to 2018: JSON + REST
Some background will help set the stage for our decision-making. When we started in 2018, we were mostly using JSON over standard REST APIs as a format for communicating between services we’d written. At the time, our priority was simple — clearing trades. We weren’t focused on data formats yet. We were in MVP mode, and JSON worked.
We knew we needed a message bus because we have multiple services that process Clear Street’s financial data, which is relatively real-time: messages come in, and we immediately need to process them and trigger events off certain jobs. Kafka is the industry standard for this sort of work. With its strong community support and strong storage guarantees, guaranteed ordering within partitions, and replay capabilities, it fits right into our vision for message bus and communication between services.
Avro, as the de facto serialization format on Kafka, was our natural starting point. It looks similar to JSON, and has similar tooling. Things were good — for a while.
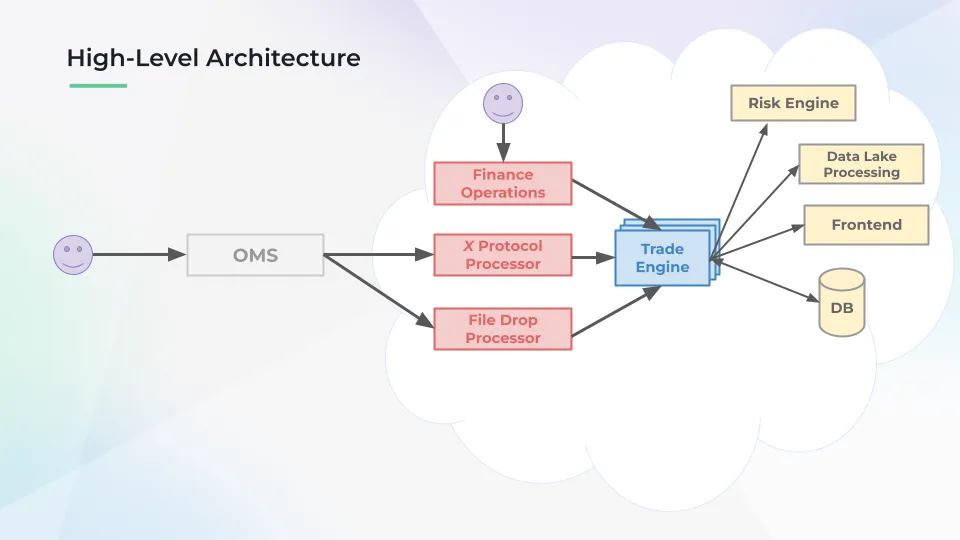
High-Level Architecture
The chart maps a clear stream of data from the user to us, and what we then do with that data — and why using stream processing (or a streaming framework) makes this approach so performant.
The smiley face on the left denotes one of our many happy clients. They use something called an OMS, or order management system, to talk to Clear Street. The blue cloud to the right of the OMS denotes Clear Street’s operations.
Three sources feed into our trade engine. Our happy finance operations team is doing internal trading, using the same tools as our customers. This X protocol processor manages anything like X format — any protocol that comes in gets processed. And, finally, people send us files, which we process. This all goes into our trade engine, which then feeds into a variety of channels: risk engine, data lake processing, our frontend, and our database.
In 2018, this process served us and our client teams just fine.
Times Change — Enter Protobuf and gRPC
By the next year, the number of microservices on Clear Street had grown significantly. We were transferring even more data over these APIs. The REST model that had worked so well was no longer fast enough.
When in doubt, look for a working model. Protobuf/gRPC was designed by Google with the scale of their own operation in mind, and gRPC is Google RPC, or remote procedure call: their way of communicating between services. Protobuf offers:
Great community support and tooling (pretty much every major company on Earth uses it)
Relatively easy move from Swagger
Good codegen
Really fast Serialization and Deserialization (SerDe) and compression
However, this wasn’t a one-click solution. At first, we only moved our APIs over to Protobuf. Avro was still in full force for Kafka and events, and our devs were increasingly frustrated by the growing number of schemas.
We had different schemas for synchronous and asynchronous events, multiple formats, and external vendors — DTCC, banks, brokers, the OCC — all on different systems. This wasn’t scalable as Clear Street kept growing.
Protobuf started to become the dominant data format at Clear Street. Simultaneously, we hit issues with Avro and our change data captures (CDCs), which took data from our database and moved it onto Kafka using Debezium. On top of that, we had problems with schema migrations using Avro that could potentially lead to massive rollbacks.
The devs continued to call out for greater simplicity. We listened.
Building an In-House Tool
We realized that switching everything to Protobuf would solve our Avro problems. Avro offers built-in data modeling tools, faster performance, and runs on just one model between APIs and events. However, there were caveats when using Protobuf on Kafka:
Tooling was either not as good or non-existent
We faced a large migration effort on the code side
There were debates as to whether we migrate historical Avro data to Protobuf
Undeterred, we stuck to our gut and went with Protobuf. The first thing we did was tackle tooling. We built an in-house tool, called “fleet” CLI (named after our repo). Here it is in action:
In this YAML format, fleet lets us define Protobuf and its properties by generating command-based code. In the above case, we’re saying “my Proto files are located in this folder,” and use this Go plugin, and fleet generates GoLang code.
We built a a full ecosystem for using Protobuf on Kafka by:
Standardizing our message format and using schemas in our headers
Increasing our debugging tools
Adding patches to a popular open source viewer, Kafka UI, to deserialize and view Protobuf
Implementing a remote schema registry using Buf.io
The Great Migration
Migrating from Avro to Protobuf was smooth, and our libraries were patched quickly. Development inertia was supported by our new trade engine, which also uses Protobuf. We saw a huge increase in network usage performance:
By transferring more compressed information, we improved our usage from an average of 32–64 kilobytes per second to only 10 or 12. Almost half of the data is being transferred, but we’re transferring the same amount of information, just more compressed. The overlap in early April was when we were running both systems at the same time.
The highlighted area shows how much time we used to spend on deserialization — it’s almost entirely gone now. We removed a full 20% of the work from the services themselves.
This Was an Experiment — at First
Going in, we knew that Kafka would work well with Protobuf, but we wondered whether the rest of the system would be happy. Our main concern was whether the tooling was enough to support developers, 100 engineers, and fast enough when it’s 3:00 AM and something’s broken?
Our inflection point was developer struggle. Our developers were dealing with eight or nine formats every day and writing hundreds of lines of code just to convert from one format to another. If we didn’t standardize, we’d spent 40% to 50% of the code on converters alone.
Much of what we’re developing is open source. For example, all the changes we made to KafkaUI are on Clear Street’s GitHub. We are in the process of making a push request back to the original authors explaining how we’d added Protobuf support to KafkaUI.
Next Steps
Our mission is to build a modern, API-based system to replace the legacy infrastructure used across the capital markets. Clear Street’s growth depends on our ability to build products fast, and iterate and innovate on small pieces. We’re now in a much better position to continue rapidly scaling our business with a much more solid foundation.
We’re building out and refining our client-facing position, risk, operations, and reporting portals. As our platform and client base grow, and our asset class diversity does so along with them, we look forward to strengthening and retooling our technology to meet our clients’ evolving needs.
Clear Street does not provide investment, legal, regulatory, tax, or compliance advice. Consult professionals in these fields to address your specific circumstances. These materials are: (i) solely an overview of Clear Street’s products and services; (ii) provided for informational purposes only; and (iii) subject to change without notice or obligation to replace any information contained therein.